认识 Horizon UI · 10/17:告警与 Incident 排查
译自英文原文:Meet Horizon UI · 10/17: Alarms & Incident Triage。
这是 Meet Horizon UI 系列的第十篇,也是第三幕 operate it 的第一篇。前几篇都在讲如何把数据看清楚:dashboard、topology、trace、log、profile。这一篇切到故障刚发生的现场。那时最要紧的问题只有两个:现在到底哪里出事了,为什么会出事?
Horizon 的告警界面抓住两件事:把重复触发归并成 incident;以及回放触发规则时的指标快照。
把重复触发归并成 incident
OAP 每次规则触发都会产生一个告警事件。忙碌服务上的抖动规则,一小时可能触发几十次;如果界面只按原始事件顺序展示,新的问题很快就会被重复事件淹没。Horizon 的归并方式更接近值班工程师看告警的方式:按 (entity, rule) 分组。比如“agent::gateway 的响应时间超过 20ms”,无论触发多少次,都是同一个 incident。
所以顶层导航里的 Alarms 页面列出的是 incident,而不是一条条事件。KPI 条统计当前 active 的 incident,包括总数和按 layer 拆分的数量;每一行展示 entity、规则消息、layer。如果同一个 incident 反复触发,还会带上 triggered N× badge。一个 incident 会处在三种状态之一:
- firing:最新一次触发还没有恢复;
- recovered:触发条件已经消失;它不再计入 active 数量,但仍会作为最近的历史记录保留;
- unstable:触发、恢复、又再次触发。
triggered N×badge 会把这种反复抖动的规则暴露出来。
Alarms 页面还使用自己的时间窗口:20m / 2h / 4h,或者最长四小时的自定义区间;它不跟全局 topbar 的时间同步。你可以回看过去两小时的告警历史,不会影响正在查看的 dashboard。
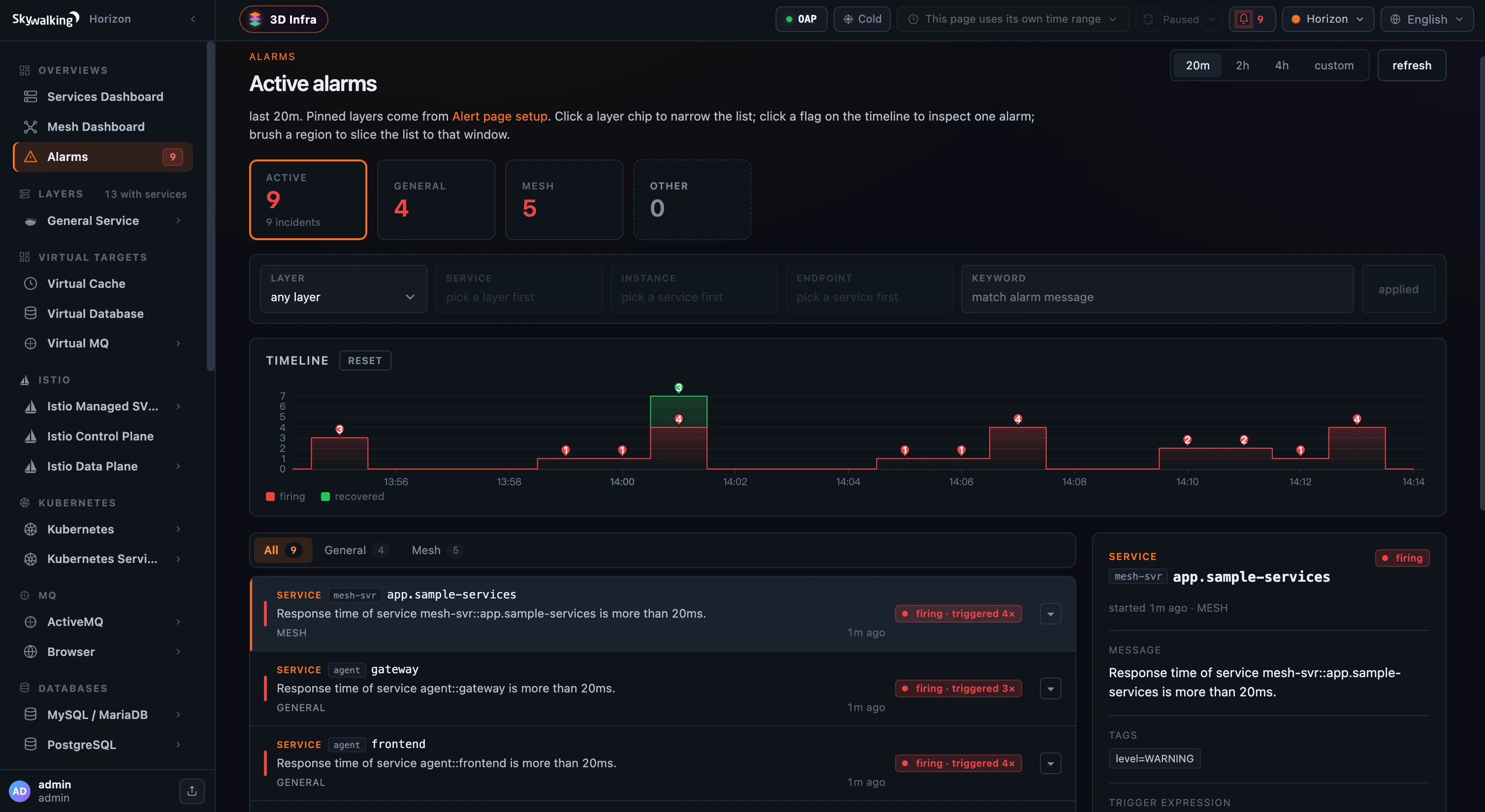 图 1:九个 active incident,而不是满屏重复告警;每一行都是一个 (entity, rule) 组合,重复触发被折叠进
图 1:九个 active incident,而不是满屏重复告警;每一行都是一个 (entity, rule) 组合,重复触发被折叠进 triggered N× badge,上方时间线展示 firing/recovered 的节奏。
回放触发证据
点开一个 incident,详情面板会做多数告警控制台做不到的事:回放证据。除了 entity、firing 状态、消息和 tags,它还会展示规则的触发表达式,也就是定义这条规则的 MQE,例如 sum(service_resp_time > 20) >= 1;以及 OAP 在触发瞬间捕获的指标快照。
这个快照不是事后再查一遍图表,而是规则评估窗口里真实参与判断的指标值,每分钟一个 bucket。Horizon 把这些点画回实时图表的时间轴上,标出触发时刻,并给快照窗口加上阴影。你看到的是到底哪些值越过阈值;不用再打开 dashboard 猜是哪次 spike 造成告警。告警本身就带着证据。
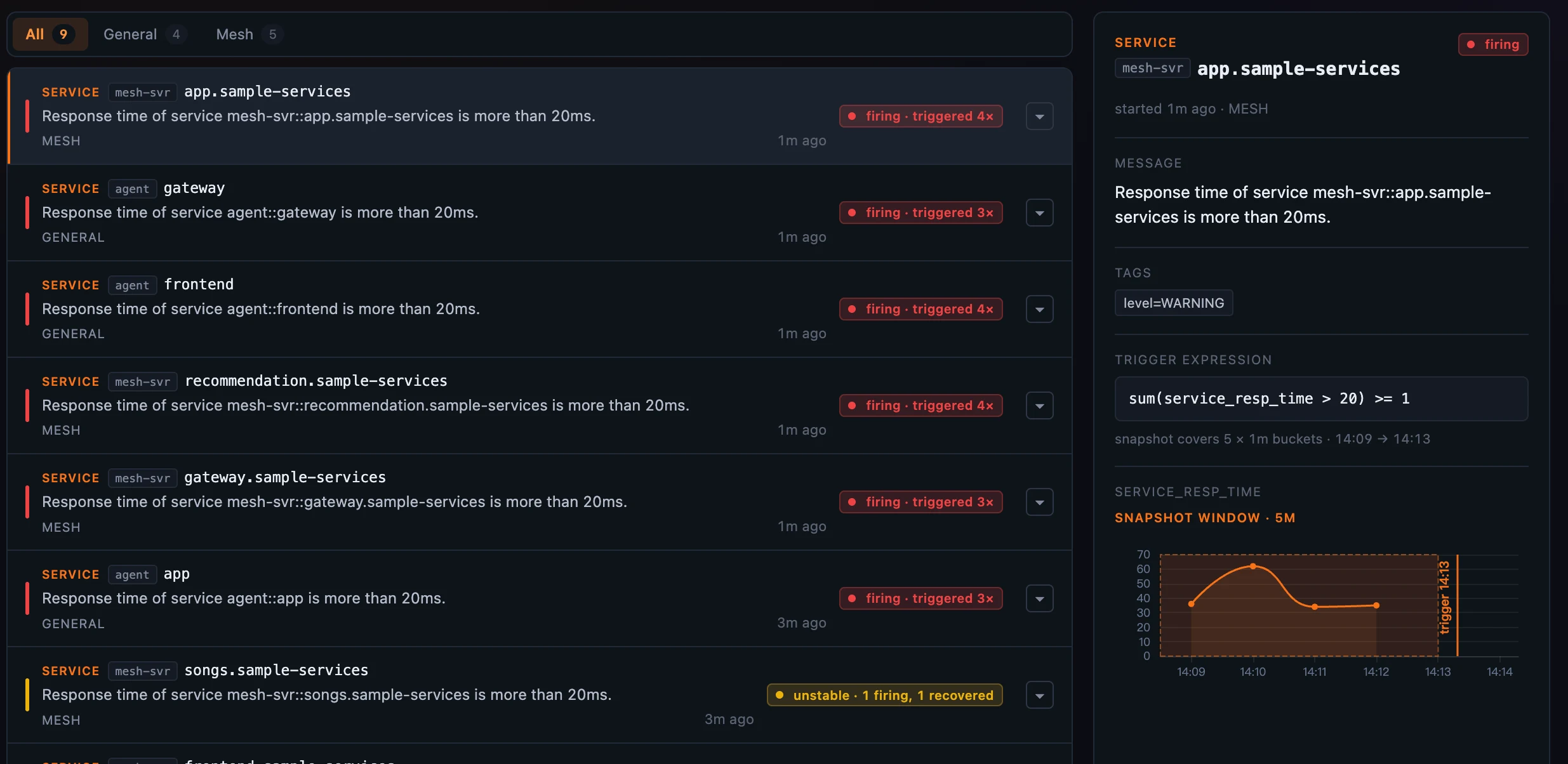 图 2:回放详情:规则的 MQE 表达式、OAP 在触发时捕获的准确数值、五分钟快照窗口(14:09→14:13)的阴影,以及触发时刻标记。左侧列表里还有一个
图 2:回放详情:规则的 MQE 表达式、OAP 在触发时捕获的准确数值、五分钟快照窗口(14:09→14:13)的阴影,以及触发时刻标记。左侧列表里还有一个 unstable · 1 firing, 1 recovered,正好是一条正在抖动的规则。
从一次触发看到完整历史
带 triggered N× 的行可以展开。点开箭头后,这个 incident 会展开成完整触发历史:#1 二十一分钟前、#2 十五分钟前,依次往下。每次触发和恢复都按时间排列。这样一眼就能区分:这是一条偶尔抖几下的规则,还是第一次告警后就一直没有恢复的问题。
列表上方的 timeline 则用分钟粒度展示整体节奏:红色表示 firing,绿色表示 recovered,每列带数量。点击 flag 可以跳到对应分钟的告警;拖拽选区则只看那段时间。timeline 会保留每个点,所以第二次 spike 不会被第一次盖住。
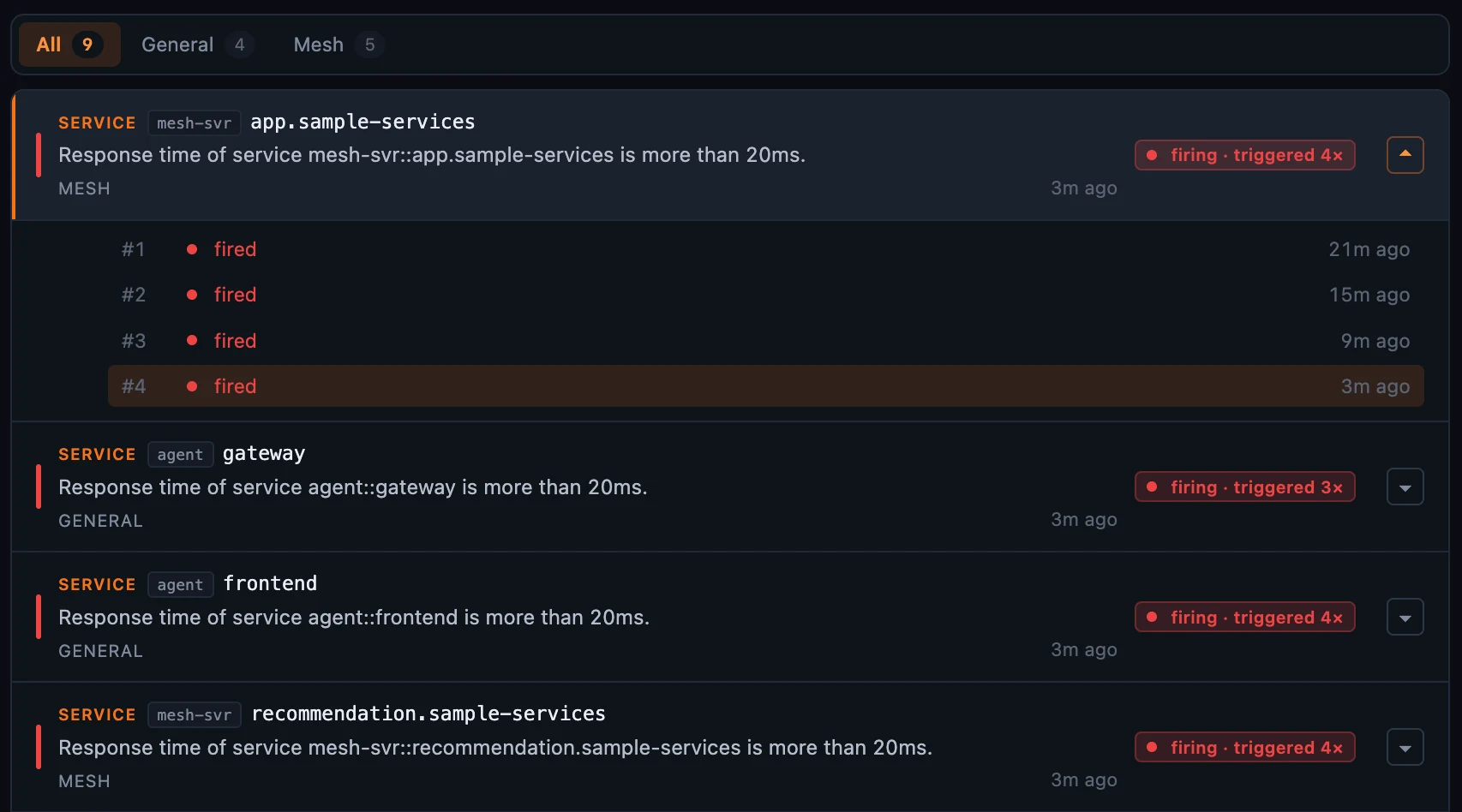 图 3:展开
图 3:展开 triggered 4× 后,可以按时间看到四次触发:从二十一分钟前的 #1 到三分钟前的 #4,而不是在页面上散落成四行。
告警不只在 Alarms 页面
Alarms 页面不是唯一入口。同一套 incident 模型还会跟着你出现在这些地方:
- topbar badge 每分钟轮询一次最近 20 分钟的滚动窗口;有 active incident 时变红并显示数量,所以你在哪个页面都能看到新问题;
- dashboard 的 Active alarms 组件列出当前 incidents,标题里带窗口(
· last 20m),避免你看到空列表时还要猜它查的是哪个时间段; - 在 service topology 和 3D Infrastructure Map 上,处于 firing 的服务会标红。
这些入口使用的是同一个滚动窗口、同一种 (entity, rule) 归并逻辑,所以 badge 上的数字、组件里的行、地图上的红点会互相对得上。
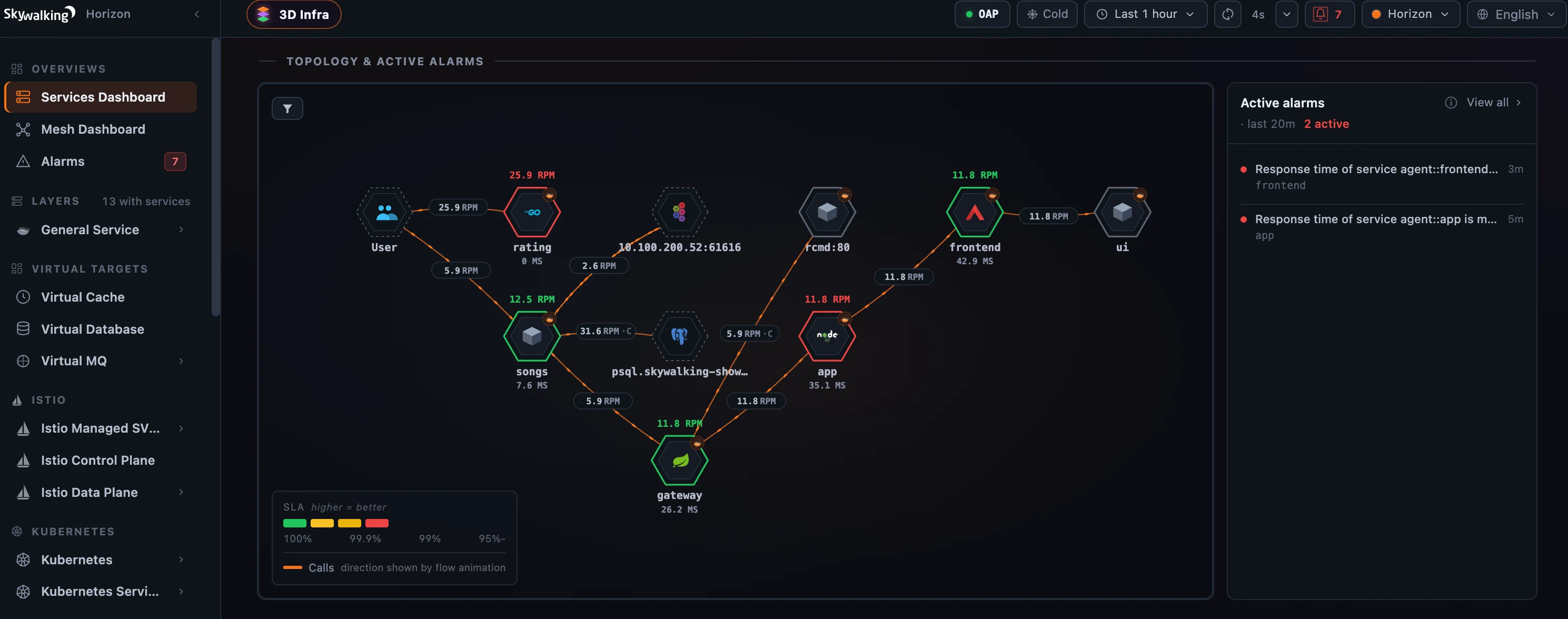 图 4:同一批 incident 出现在不同入口:topbar badge、topology 上带红圈的服务,以及 Active alarms 组件,都读取同一个 20 分钟滚动窗口。
图 4:同一批 incident 出现在不同入口:topbar badge、topology 上带红圈的服务,以及 Active alarms 组件,都读取同一个 20 分钟滚动窗口。
它在哪里运行,又刻意不做什么
读取 active alarms 是纯 observe 操作:数据来自 OAP 的 query host,当前 OAP 上不需要额外配置;查看受 alarms:read 权限控制。你可以按关键词收窄列表;如果 OAP 暴露了新版 alarm query,也可以按 layer 和 entity 过滤。
有两件事是 Horizon 有意不做的。第一,Horizon alarms 只是 OAP 评估状态的只读镜像:没有 acknowledge-and-dismiss;只有条件真的清除,incident 才会 recovered。所以这个页面呈现的是事实状态,不是一个靠人手清理的待办列表。第二,这里不编辑告警规则;规则仍然在 OAP 的 alarm-settings.yml。实时规则上下文——哪个 OAP node 在评估哪个 entity,以及 silence 和 recovery-observation 的倒计时——属于 Alerting Rules 界面。那个界面走 OAP admin host,是下一篇的主题。
后续阅读
字段参考,包括窗口上限、快照内部结构和 pinned-layer 配置,可以看 Alarms 文档。
下一篇:运行时规则与实时调试:通过 OAP admin host,用真实数据编辑并验证 OAL / MAL / LAL。